
At their Advancing AI conference, AMD announced the MI350/355 GPUs along with a few specs. SemiAccurate has a technical piece coming but for now we will just cover the high level specs.

More power leads to more performance
The most obvious question is what is the difference between the MI350 and MI355? That answer is easy, MI350 is air cooled, MI355 is direct liquid cooled (DLC). Because of this the MI350 is capped at 1000W and the MI355 will sip a mere 1400W. According to the raw AMD numbers, the performance difference is about 10% on a raw flops basis but the real world delta is more towards 20% at the system level. Depending on how AMD prices things, the MI355 seems to be the no-brainer choice.

MI350 construction is similar but different
MI35x itself is a ground up new architecture for the device but the platform itself remains pretty close to the existing MI300 variants. The same can’t be said at the silicon level where there was one big architectural change, the base/IO die. MI300 had four IODs, one per compute die. This worked out fine and brought a lot of flexibility to the family. You could mix and match CPU and GPU tiles on whim and AMD did just that. Unfortunately the market didn’t care, or at least care enough to warrant future heterogeneous CPU/GPU hybrids.
Without the need for this level of flexibility, and with packaging advances, AMD moved to a two IOD architecture. Each IOD has two CCDs/XCDs on top which still allows them to mix and match CPU and GPU but only two at a time. That said we don’t expect to see a CPU bearing MI35x device this generation. This change also leads to some more interesting memory choices but that is a topic for another article.
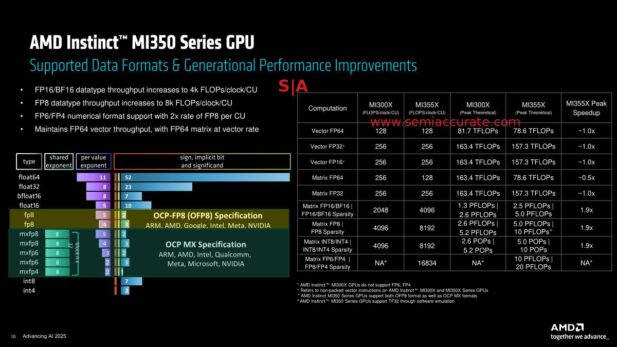
AMD’s per-CU performance comparison
At a low level, the per-CU performance is broadly the same on MI35x as it was on MI300, at least for traditional data types. On the newer and much more broadly used AI datatypes such as BF16 and lower INT widths, the MI35x doubles the performance of it’s predecessor. Do note this is per CU, not per device. Each Accelerator Complex Die (XCD) has 256 active CUs per die which is down from 304 in the MI300 generation but net performance goes way up.
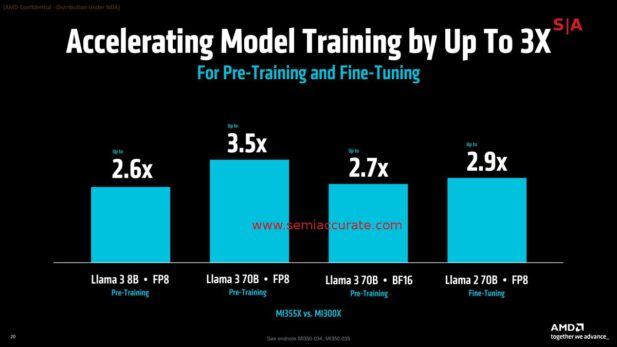
If you want to train Llama 3 yourself…..
AMD is claiming ~3x performance gains over MI300 in Llama 3 training but benchmarks on this scale can be a little murky. This isn’t a criticism, it is just not easy compare things on this scale independently for obvious reasons. In any case the advances that MI35x brings to the table are real and come from a mix of low level hardware advances, device advances, memory, IO, and software changes. In short the end user visible performance gains should be more than 2x and exceed that with some software work.
Overall the MI35x family isn’t a sea change over the MI300 generation but it it brings some serious advances to the table. Hardware isn’t the most important factor for AI purchases to many customers, software often is. AMD hasn’t ignored this front either with the release of ROCM7 and various other tools and frameworks. The overall result is a claimed leap in training performance and a large perf/dollar advantage over Nvidia. It will be interesting to see how it all plays out in the market.S|A

{kind=link}