
Anomaly detection in cybersecurity has long promised the ability to identify threats by highlighting deviations from expected behavior. When it comes to identifying malicious commands, however, its practical application often results in high rates of false positives – making it expensive and inefficient. But with recent innovations in AI, is there a new angle that we have yet to explore?
In our talk at Black Hat USA 2025, we presented our research into developing a pipeline that does not depend on anomaly detection as a point of failure. By combining anomaly detection with large language models (LLMs), we can confidently identify critical data that can be used to augment a dedicated command-line classifier.
Using anomaly detection to feed a different process avoids the potentially catastrophic false-positive rates of an unsupervised method. Instead, we create improvements in a supervised model targeted towards classification.
Unexpectedly, the success of this method did not depend on anomaly detection locating malicious command lines. Instead, anomaly detection, when paired with LLM-based labeling, yields a remarkably diverse set of benign command lines. Leveraging these benign data when training command-line classifiers significantly reduces false-positive rates. Furthermore, it allows us to use plentiful existing data without the needles in a haystack that are malicious command lines in production data.
In this article, we’ll explore the methodology of our experiment, highlighting how diverse benign data identified through anomaly detection broadens the classifier’s understanding and contributes to creating a more resilient detection system.
By shifting focus from solely aiming to find malicious anomalies to harnessing benign diversity, we offer a potential paradigm shift in command-line classification strategies.
Cybersecurity practitioners typically have to strike a balance between costly labeled datasets and noisy unsupervised detections. Traditional benign labeling focuses on frequently observed, low-complexity benign behaviors, because this is easy to achieve at scale, inadvertently excluding rare and complicated benign commands. This gap prompts classifiers to misclassify sophisticated benign commands as malicious, driving false positive rates higher.
Recent advancements in LLMs have enabled highly precise AI-based labeling at scale. We tested this hypothesis by labelling anomalies detected in real production telemetry (over 50 million daily commands), achieving near-perfect precision on benign anomalies. Using anomaly detection explicitly to enhance the coverage of benign data, our aim was to change the role of anomaly detection – shifting from erratically identifying malicious behavior to reliably highlighting benign diversity. This approach is fundamentally new, as anomaly detection traditionally prioritizes malicious discoveries rather than enhancing benign label diversity.
Using anomaly detection paired with automated, reliable benign labeling from advanced LLMs, specifically OpenAI’s o3-mini model, we augmented supervised classifiers and significantly enhanced their performance.
Data collection and featurization
We compared two distinct implementations of data collection and featurization over the month of January 2025, applying each implementation daily to evaluate performance across a representative timeline.
Full-scale implementation (all available telemetry)
The first method operated on full daily Sophos telemetry, which included about 50 million unique command lines per day. This method required scaling infrastructure using Apache Spark clusters and automated scaling via AWS SageMaker.
The features for the full-scale approach were based primarily on domain-specific manual engineering. We calculated several descriptive command-line features:
- Entropy-based features measured command complexity and randomness
- Character-level features encoded the presence of specific characters and special tokens
- Token-level features captured the frequency and significance of tokens across command-line distributions
- Behavioral checks specifically targeted suspicious patterns commonly correlated with malicious intent, such as obfuscation techniques, data transfer commands, and memory or credential-dumping operations.
Reduced-scale embeddings implementation (sampled subset)
Our second strategy addressed scalability concerns by using daily sampled subsets with 4 million unique command lines per day. Reducing the computational load allowed for the evaluation of performance trade-offs and resource efficiencies of a less expensive approach.
Notably, feature embeddings and anomaly processing for this approach could feasibly be executed on inexpensive Amazon SageMaker GPU instances and EC2 CPU instances – significantly lowering operational costs.
Instead of feature engineering, the sampled method used semantic embeddings generated from a pre-trained transformer embedding model specifically designed for programming applications: Jina Embeddings V2. This model is explicitly pre-trained on command lines, scripting languages, and code repositories. Embeddings represent commands in a semantically meaningful, high-dimensional vector space, eliminating manual feature engineering burdens and inherently capturing complex command relationships.
Although embeddings from transformer-based models can be computationally intensive, the smaller data size of this approach made their calculation manageable.
Employing two distinct methodologies allowed us to assess whether we could obtain computational reductions without considerable loss of detection performance — a valuable insight toward production deployment.
Anomaly detection techniques
Following featurization, we detected anomalies with three unsupervised anomaly detection algorithms, each chosen due to distinct modeling characteristics. The isolation forest identifies sparse random partitions; a modified k-means uses centroid distance to find atypical points that don’t follow common trends in the data; and principal component analysis (PCA) locates data with large reconstruction errors in the projected subspace.
Deduplication of anomalies and LLM labeling
With preliminary anomaly discovery completed, we addressed a practical issue: anomaly duplication. Many anomalous commands only differed minimally from each other, such as a small parameter change or a substitution of variable names. To avoid redundancies and inadvertently up-weighting certain types of commands, we established a deduplication step
We computed command-line embeddings using the transformer model (Jina Embeddings V2), then measured the similarity of anomaly candidates with cosine similarity comparisons. Cosine similarity provides a robust and efficient vector-based measure of semantic similarity between embedded representations, ensuring that downstream labelling analysis focused on substantially novel anomalies.
Subsequently, anomalies were classified using automated LLM-based labeling. Our method used OpenAI’s o3-mini reasoning LLM, specifically chosen for its effective contextual understanding of cybersecurity-related textual data, owing to its general-purpose fine-tuning on various reasoning tasks.
This model automatically assigned each anomaly a clear benign or malicious label, drastically reducing costly human analyst interventions.
The validation of LLM labeling demonstrated an exceptionally high precision for benign labels (near 100%), confirmed by subsequent expert analyst manual scoring across a full week of anomaly data. This high precision supported direct integration of labeled benign anomalies into subsequent phases for classifier training with high trust and minimal human validation.
This carefully structured methodological pipeline — from comprehensive data collection to precise labeling — yielded diverse benign-labeled command datasets and significantly reduced false-positive rates when implemented in supervised classification models.
The full-scale and reduced-scale implementations resulted in two separate distributions as seen in Figures 1 and 2 respectively. To demonstrate the generalizability of our method, we augmented two separate baseline training datasets: a regex baseline (RB) and an aggregated baseline (AB). The regex baseline sourced labels from static, regex-based rules and was meant to represent one of the simplest possible labeling pipelines. The aggregated baseline sourced labels from regex-based rules, sandbox data, customer case investigations, and customer telemetry. This represents a more mature and sophisticated labeling pipeline.
Figure 1: Cumulative distribution of command lines gathered per day over the test month using the full-scale method. The graph shows all command lines, deduplication by unique command line, and near-deduplication by cosine similarity of command line embeddings
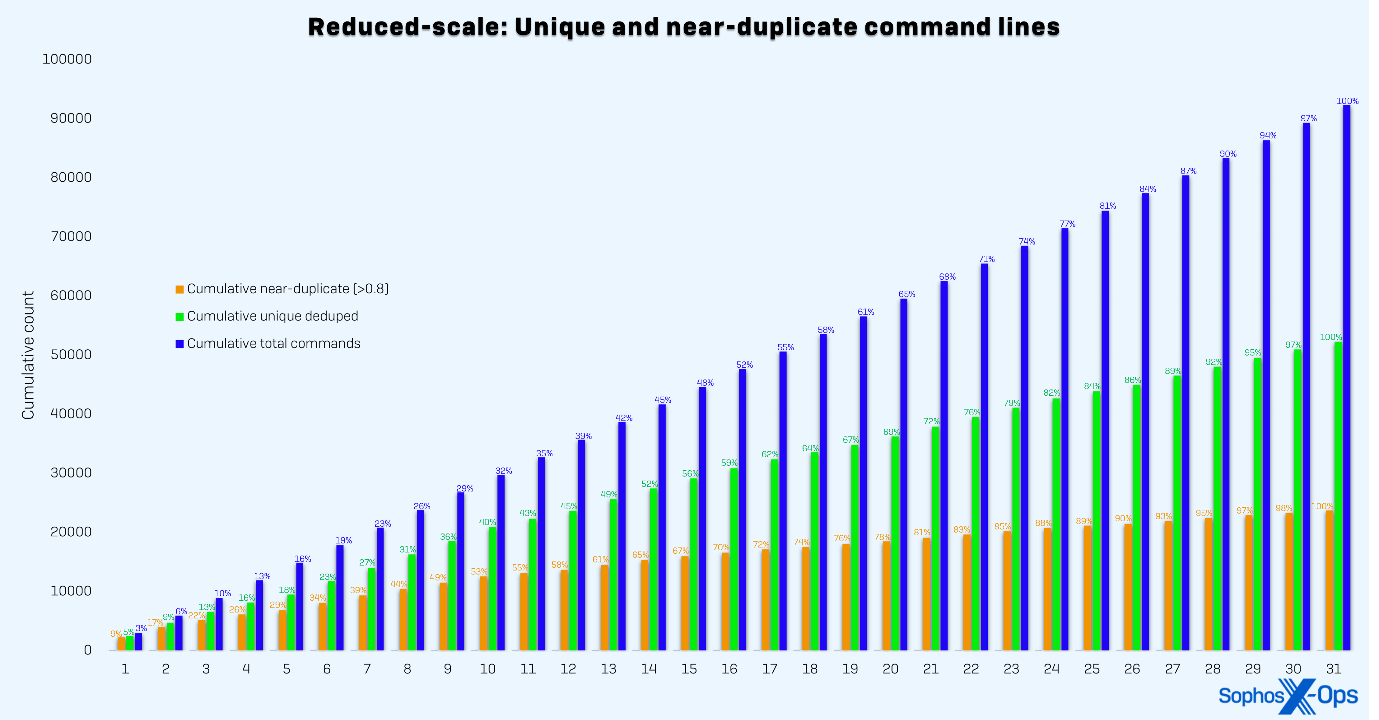
Figure 2: Cumulative distribution of command lines gathered per day over the test month using the reduced-scale method. The reduced scale plateaus slower because the sampled data is likely finding more local optima
| Training set | Incident test AUC | Time split test AUC |
| Aggregated Baseline (AB) | 0.6138 | 0.9979 |
| AB + Full-scale | 0.8935 | 0.9990 |
| AB + Reduced-scale Combined | 0.8063 | 0.9988 |
| Regex Baseline (RB) | 0.7072 | 0.9988 |
| RB + Full-scale | 0.7689 | 0.9990 |
| RB + Reduced-scale Combined | 0.7077 | 0.9995 |
Table 1: Area under the curve for the aggregated baseline and regex baseline models trained with additional anomaly-derived benign data. The aggregated baseline training set consists of customer and sandbox data. The regex baseline training set consists of regex-derived data
As seen in Table 1, we evaluated our trained models on both a time split test set and an expert-labeled benchmark derived from incident investigations and an active learning framework. The time split test set spans three weeks immediately succeeding the training period. The expert-labeled benchmark closely resembles the production distribution of previously deployed models.
By integrating anomaly-derived benign data, we improved the area under the curve (AUC) on the expert-labeled benchmark of the aggregated and regex baseline models by 27.97 points and 6.17 points respectively.
Instead of ineffective direct malicious classification, we demonstrate anomaly detection’s exceptional utility in enriching benign data coverage in the long tail – a paradigm shift that enhances classifier accuracy and minimizes false-positive rates.
Modern LLMs have enabled automated pipelines for benign data labelling – something not possible until recently. Our pipeline was seamlessly integrated into an existing production pipeline, highlighting its generic and adaptable nature.

{kind=link}